GPT1: Improving Language Understanding by Generative Pre-Training - 论文精读学习笔记
You are what you eat.
And I'm cooking what I eat! :)
目录
GPT1: Improving Language Understanding by Generative Pre-Training - 论文精读学习笔记介绍数据集相关工作框架3.1 无监督学习下的预训练(Unsupervised pre-training)3.2 监督学习下的微调 (Supervised fine-tuning)3.3 特定任务的输入转换(Task-specific input transformations)不同微调任务的输入Textual entailmentSimilarityQuestion Answering and Commonsense Reasoning实验4.1 实验设置无监督预训练模型规范微调细节4.2 监督微调自然语言推理(Natural Language Inference)问题回答和常识推理语义相似性(Semantic Similarity)分类(Classification)分析层的影响(Impact of number of layers transferred)消融实验如何应用GPT模型总结原文目录参考博文
提前说明:本系列博文主要是对参考博文的解读与重述(对重点信息进行标记、或者整段摘录加深自己的记忆和理解、融合多个博文的精髓、统合不同的代表性的案例),仅做学习记录笔记使用。与君共享,希望一同进步。
预备知识
语言理解(Language Understanding)
语言理解是指计算机能够理解人类语言的含义和上下文信息,从而进行后续的信息处理和决策。在本文中,语言理解被作为研究的核心问题。
生成式预训练(Generative Pre-Training)
生成式预训练是一种机器学习方法,通过让模型预测一段文本的后续内容来学习语言的结构和语义信息。在本文中,生成式预训练被用于提高语言理解能力。
生成式预训练方式使得模型能够捕捉到语言结构、语义和上下文信息,从而提升了对语言的理解能力。
核心思想 生成式预训练的核心思想是:通过生成连贯的文本,让模型学会捕捉语言的内在规律。在预训练阶段,模型接受一系列文本序列作为输入,然后尝试预测下一个词。这种预测过程迫使模型去理解文本的语义和上下文信息,从而实现对语言的理解。在生成式预训练过程中,模型不断优化其生成文本的能力,从而提升了对语言的理解能力。
Transformer
Transformer模型是一种基于自注意力机制的深度学习模型,被广泛用于各种自然语言处理任务,包括生成式预训练。在本文中,GPT系列模型采用了Transformer架构。
Fine-tuning(微调)
微调是指在预训练模型的基础上,针对特定任务进行参数调整和优化,从而使得模型能够更好地适应特定领域的需求。在本文中,微调被用于提高语言模型的性能。
评估(Evaluation)
评估是指对模型在特定任务上的表现进行定量和定性分析,以衡量模型的性能和效果。在本文中,作者采用了多种评估指标来衡量模型的性能。
全文梗概
ChatGPT的初代工作,可以说没有GPT,就没有现在的大模型百家争鸣,关注并思考作者是如何根据前者的工作在思想上进行创新,从而得到通用的模型架构。
GPT通过无监督预训练和监督微调,探索了一种用于语言理解任务的半监督学习/训练方法。目标是学习通用的表示,可以迁移到任何任务。展示了在自然语言理解任务上的强大性能,特别是在NLU、QA和语义相似性任务上。该模型使用Transformer解码器,通过预训练捕获语言结构,然后针对特定任务进行微调。这一方法为后来的BERT等模型奠定了基础,推动了NLP领域的发展。
本文主要探讨了利用生成式预训练方法提高语言理解能力的问题。
本文主要介绍了GPT1模型(利用Transformer架构),该模型通过无监督的生成式(Generative)预训练(Pre-Training)和有监督的微调(Fine-Tuning)提升语言理解能力。得到了适应多种NLP下游任务的模型。
在预训练阶段,使用Transformer架构预测序列中的下一个token;
然后在标记数据集上进行微调。
适用于文本分类、相似度分析等NLP任务。GPT1展示了生成预训练的有效性,成为后续大语言模型如GPT2、GPT3和ChatGPT的基石。
核心思想 先在大规模的无标注文本上预训练一个语言模型,然后在每个具体任务上进行判别式微调,同时利用任务相关的输入变换来实现有效的迁移学习。
训练方法 该论文采用了半监督的训练方式,即通过无监督学习进行预训练,再通过监督学习进行微调。在评估了RNN网络和Transformer网络之后,作者发现后者可以很好地捕捉较长的语言结构,从而使得模型在处理子任务时具有更好的泛化性。这种方法为模型的训练带来了很好的效果。
训练思路 论文提出了一个新的训练思路:先基于海量无标注语料进行通用的生成式预训练,然后针对下游任务使用有标注的数据进行微调。这算是一个两阶段的半监督训练方法,先后融合了无监督的预训练和有监督的微调。
意思是:作者对比了RNN和Transformer,选择了Transformer!
主要做法 使用Transformer的解码部分 + 把结构化的文本输入变成序列,预训练 + task-discriminative fine-tuning解决自然语言理解问题。
介绍
数据集
自然语言理解任务包括哪些:
文本关联
常识推理 —— Stories Cloze Test
问题解答 —— RACE
语义相似性评估
文档分类
文本引申 —— MultiNLI
...
现在的问题:虽然大量未标注的文本语料库非常丰富,但用于学习这些特定任务的标注数据却非常稀少,这使得经过鉴别训练的模型难以充分发挥作用。
文章在包括文本分类、文本相似度分析、问答和知识推理四个任务的数据集上进行了数值实验。
结果表明,生成式预训练在9/12个数据集上取得了State-of-the-art(SOTA)水平。
问题 如何利用无标注的大量数据!
文章贡献:文章证明,通过在各种未标注文本语料库上对语言模型进行生成式预训练(Generative Pre-Training),然后在每个特定任务上进行判别式微调(Discriminative Fine-Tuning),可以在这些任务上取得巨大的收益。
文章提出的GPT训练方式是当前LLM的一种主流训练方式。
提出了一种基于生成式预训练的语言理解模型,该模型可以在各种自然语言处理任务上取得显著的性能提升。
特别之处:与以往的方法不同,我们在微调过程中利用任务感知输入转换来实现有效的转移,同时只需对模型架构做最小的改动。
不是很明白,上一句这个是啥意思~~
结论:。我们在各种自然语言理解基准上证明了我们方法的有效性。在所研究的 12 项任务中,我们的通用任务无关模型在 9 项任务中的表现明显优于使用专为每项任务设计的架构的判别训练模型。
利用未标注文本数据的难点:
不清楚什么样的预训练有助于文本的迁移学习;
如何将学习到的表示转移到下游任务。
相关工作
用于 NLP 的半监督学习 | Semi-supervised learning for NLP 我们的工作大致属于自然语言半监督学习的范畴。这一范式已引起了极大的兴趣,并被应用于序列标注 [24, 33, 57] 或文本分类 [41, 70] 等任务中。最早的方法是使用未标注的数据来计算词级或短语级统计数据,然后将其作为有监督模型的特征[33]。在过去几年中,研究人员已经证明了使用词嵌入[11, 39, 42]的好处,这种方法是在无标签语料库中训练出来的,可以提高各种任务的性能[8, 11, 26, 45]。不过,这些方法主要传递的是词层面的信息,而我们的目标是捕捉更高层次的语义。
最近的一些方法研究了从未标明的数据中学习和利用词级语义以外的语义的方法。短语级或句子级嵌入可以使用未标记的语料库进行训练,已被用于将文本编码为适合各种目标任务的向量表示[28, 32, 1, 36, 22, 12, 56, 31]。
发展过程:
1 使用未标注的数据来计算词级或短语级统计数据,然后将其作为有监督模型的特征。
2 使用词嵌入:在无标签语料库中训练出来的,可以提高各种任务的性能。
目标:(1 和 2 都是传递的是词层面的信息) → (为了捕捉更高层次的语义3 )
3 从未标明的数据中学习和利用词级语义以外的语义的方法 —— 短语级或句子级嵌入:可以使用未标记的语料库进行训练,已被用于将文本编码为适合各种目标任务的向量表示。
无监督预训练 | Unsupervised pre-training 无监督预训练是半监督学习的一种特殊情况,其目标是找到一个好的初始化点,而不是修改监督学习目标。
早期的研究探索了该技术在图像分类和回归任务中的应用。随后的研究表明,预训练可以作为一种正则化方案,使深度神经网络具有更好的泛化能力。在最近的工作中,该方法被用于训练各种任务的深度神经网络,如图像分类、语音识别、实体消歧和机器翻译。
与我们的工作最接近的是使用语言建模目标对神经网络进行预训练,然后在目标任务的监督下对其进行微调。Dai 等人 [13] 以及 Howard 和 Ruder [21] 采用这种方法来改进文本分类。
本文特色 不过,虽然预训练阶段有助于捕捉一些语言信息,但他们使用的 LSTM 模型将其预测能力限制在较短的范围内。相比之下,我们选择的变压器网络可以捕捉到更长距离的语言结构,这在我们的实验中得到了证明。
此外,我们还在自然语言推理、转述检测和故事补全等更广泛的任务中证明了我们模型的有效性。其他方法 [43, 44, 38] 使用预先训练好的语言或机器翻译模型中的隐藏表征作为辅助特征,同时在目标任务上训练监督模型。这就需要为每个单独的目标任务设置大量新参数,而我们在传输过程中只需对模型架构做最小的改动。
辅助训练目标 | Auxiliary training objectives 添加辅助无监督训练目标是半监督学习的另一种形式。Collobert 和 Weston [10] 的早期研究使用了 POS 标记、分块、命名实体识别和语言建模等多种辅助 NLP 任务来改进语义角色标记。最近,Rei [50] 在他们的目标任务目标中添加了一个辅助语言建模目标,并在序列标注任务中证明了性能的提高。我们的实验也使用了辅助目标,但正如我们所展示的,无监督预训练已经学习了与目标任务相关的几个语言方面。
框架
训练(半监督的训练方式)程序包括2个阶段:
预训练阶段:在大型文本语料库中学习高容量语言模型 —— 在无监督数据上进行预训练;
※ 在海量文本上训练,无需label,根据前k-1个词预测到第k个单词是什么,第一阶段的训练让模型拥有了更多的先验知识,模型具有非常强的泛化性。
微调阶段:将模型调整为使用标注数据的判别任务 —— 再在特定任务的监督数据上进行微调。
※ 在特定任务(有label的数据集)上fine-tuning,让模型能适应不同的任务,提高模型在特定任务上的准确性。
具体来说就是替换掉第一阶段的最后一层,在监督数据集上训练。
本文模型采用Transformer的解码器,迁移过程采用特定于任务的自回归方法,该方法将结构化文本处理为连续的token序列,在不改变模型架构的情况下进行微调。
3.1 无监督学习下的预训练(Unsupervised pre-training)
如何利用无监督学习进行预训练:
在这个过程中,GPT模型通过预测一段文本的后续内容来学习语言的结构和语义信息。
文章提出了通过生成式预训练来学习语言结构,即,通过前面的token预测当前的token,结构化表示如下公式:
给定未标注的语料序列
其中,
给定一组token的输入,通过多头自回归注意力机制实现下一个token的预测。
其中,
模型整体工作介绍 此外,模型仅使用了Transformer的解码器(Decoder)进行预训练。预测过程涉及将
通俗来说,上面的式子就是:希望模型生成的句子尽量靠近当前句子。
神经网络采用多层Transformer解码架构,相比于传统Transformer采用sin函数进行位置编码,这里通过模型学习到位置嵌入(position embedding)。其他部分于Transformer解码部分基本一致。
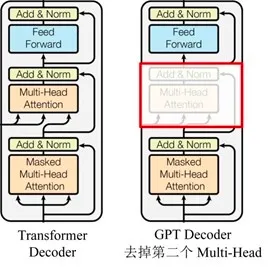
注意 对于生成来说,跟原始Transformer论文不同的是,这里只用到了Transformer decoder,并在decoder中去掉了前一encoder的输入的multi-head attention部分。
本文的模型是多层Transformer解码器堆叠的模型,该模型对输入带有位置编码的上下文应用多头注意力机制,输出目标token的分布:
其中,
3.2 监督学习下的微调 (Supervised fine-tuning)
如何将预训练好的GPT模型应用于语言理解任务中(包括文本分类、命名实体识别等任务):
→ 在这个过程中,GPT模型通过将输入文本转换为向量表示,然后利用已学习的语言结构和语义信息进行分类或实体识别等任务。
得到预训练模型之后,我们将模型在有标签的数据集
首先将序列
需要最大化的目标为:
博文5 需要注意的是fine-tuning中也要考虑模型的通用性,所以增加了一个辅助学习目标(Auxiliary Learning Objective),这里对应的是预训练模型的
fine-tuning过程中不是对所有参数进行更新,只对参数矩阵
此外,作者还发现,将语言建模作为微调的辅助目标有利于提升模型的泛化性并加速学习(提高监督模型的泛化 + 加速收敛),即,作者没有只将
其中,
Notes 以上损失函数是针对微调任务生效的,而不是说每次都要重新训练大模型。
还可以将目标函数进行加权求和呢!
3.3 特定任务的输入转换(Task-specific input transformations)
文章整体架构
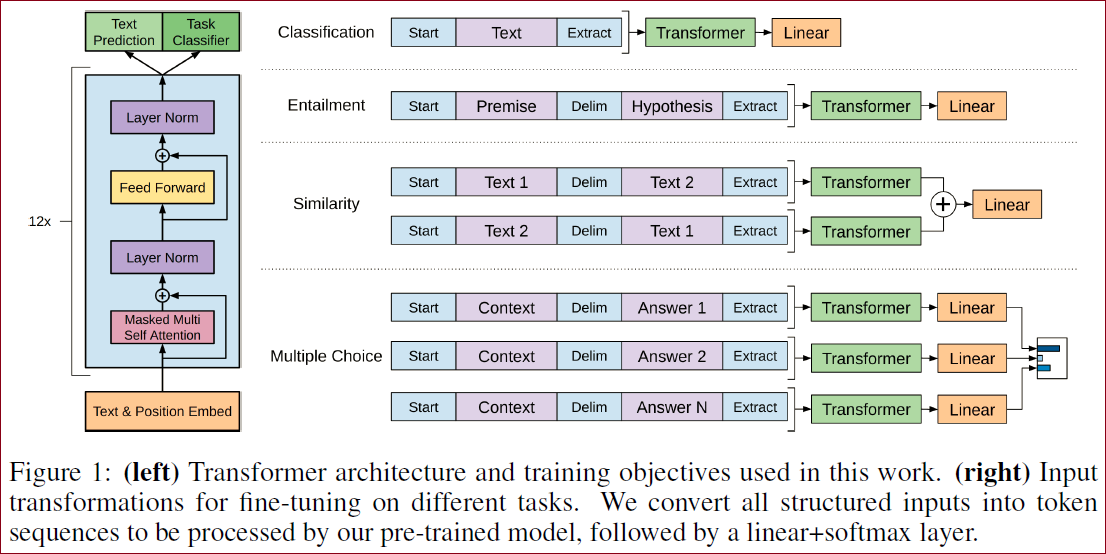
图1:(左)本工作中使用的Transformer架构和训练目标。(右)用于对不同任务进行微调的输入转换。我们将所有结构化输入转换为token序列,由我们的预训练模型处理,然后跟上一个线性层和softmax层。
上图展示了如何将模型应用到特定问题下。核心包括2个过程:
对输入的token序列进行预处理,根据任务加入特殊的token构造可以处理的有序序列;
对输出部分构建一个线性层,将Transformer的输出映射到对应的标签或者词表上。
上图展示了文中说明的四种特定任务,通过添加的线性层(Linear),也是上文说的
下游任务的输入格式统一 (方便迁移的时候不用变动太大)
下游任务的输入格式不统一的话,对于不同NLP下游任务进行迁移学习时通常都要在网络中增加新的任务相关的模块,为了达到Transformer网络格式针对不同NLP下游任务不变的目标,这里对不同的NLP下游任务输入格式进行了统一处理。
分类(Classification):输入开始符(Start),文本(Text),抽取符(Extract),线性层即输出分类数。
包含(Entailment):输入开始符(Start),前提(Premise),分隔符(Delim),假设(Hypothesis),抽取符(Extract),线性层输出类似包含、不包含、无关三分类;
相似(Similarity):输入开始符(Start),文本(Text1),分隔符(Delim),文本(Text2),抽取符(Extract);输入开始符(Start),文本(Text2),分隔符(Delim),文本(Text1),抽取符(Extract)。经过相加后进入线性层,输出两段文本在不同语境下是否相似。(最终输出在linear操作前进行了element-wise操作。)
多选(Multiple Choice):输入开始符(Start),文本(Context),分隔符(Delim),答案(Answer 1),抽取符(Extract);输入开始符(Start),文本(Context),分隔符(Delim),答案(Answer N),抽取符(Extract);每个输入都经过一个线性层而后通过softmax操作求出每个答案的置信度。
不同微调任务的输入
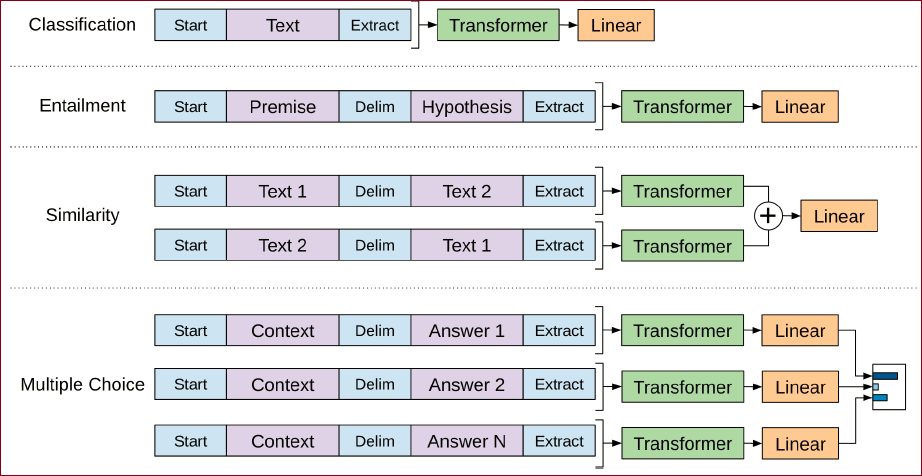

针对不同的微调任务,文章采用了traversal-style方法,即,将所有输入转化为一个有序的句子(Start标志句子开始,Extract标志句子结束),从而模型可以直接处理。具体的不同任务的处理方式如上图。
文本分类(Classification):直接输入当前句子;
知识推理:输入Premise + Hypothesis,用Delim分隔;
文本相似度:输入两个句子—Text1 + Text2 和 Text2 + Text1,均用Delim分隔,再用线性层将其结合;
问答:输入每个可能答案的句子上下文+答案,分别送入不同的线性层,最后均喂给模型。
Textual entailment
对于文本蕴含任务,将前提和假设连接到一起,中间用分隔符分割。
Similarity
对于相似性任务,序列的排序没有关联,因此对两种排序都进行了独立建模,将最后一层的输出相加喂入MLP。
Question Answering and Commonsense Reasoning
对于问题回答和常识推理任务,给定上下文内容和问题,以及一组回答,将上下文与问题和每个回答相连接,两两之间都需要特殊的分隔符,最后将所有组合的输出结果通过softmax层标准化,得到答案的分布。
实验
4.1 实验设置
无监督预训练
作者采用BooksCorpus数据集训练语言模型。
该数据集包含超过7000部未发表的书籍。
书籍中的内容包含长段的连续文本,因此可以学习远程信息。
使用BooksCorpus语料包含很多连续长文本,便于学习到很长范围的信息。
模型规范
模型采用12层Transformer解码器,每一层包含768维的网络进行训练。
使用了3072维数的FFN(Position-wise Feed-Forward Network)层;
使用了Adam优化器;
激活函数采用高斯误差线性单元(GELU),其中使用了4000个合并的字节对编码(BPE);
位置编码采用自学习的位置嵌入(learned position embedding)。
微调细节
...
4.2 监督微调

本文进行实验的NLP任务。
自然语言推理(Natural Language Inference)
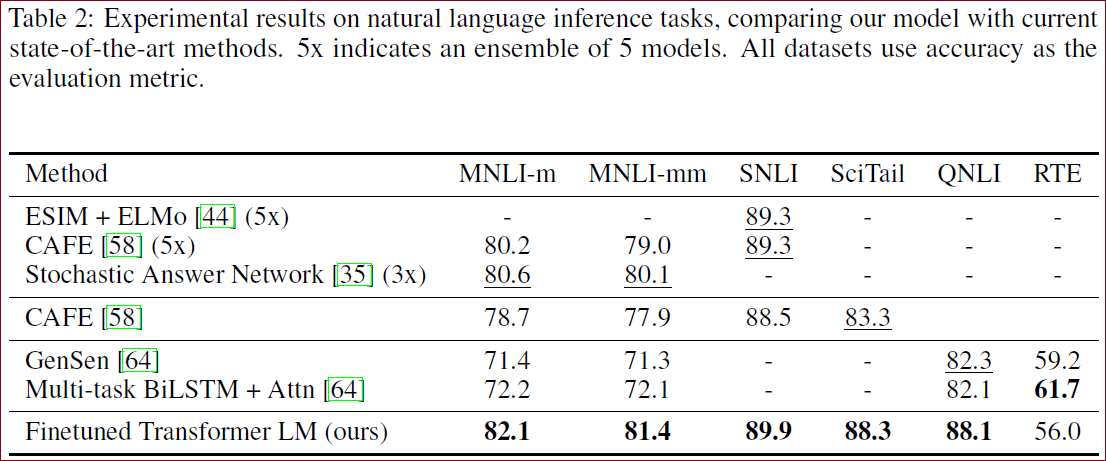
自然语言推理任务的结果,GPT在五个数据集中的四个上显著优于基线,但是在RTE上低于多任务biLSTM,可能的原因是本文的模型没进行多任务上训练。
问题回答和常识推理
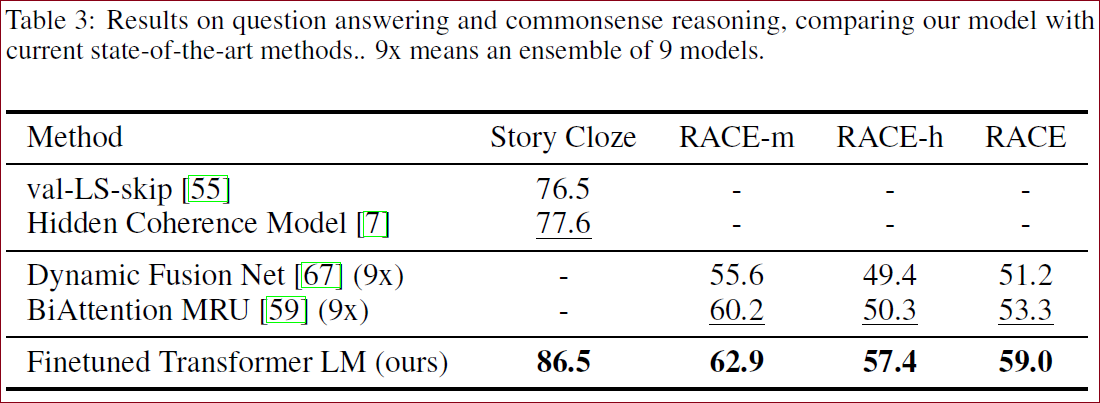
在问答和常识推理上,GPT显著高于其他模型,证明模型有效处理远程上下文的能力。
语义相似性(Semantic Similarity)
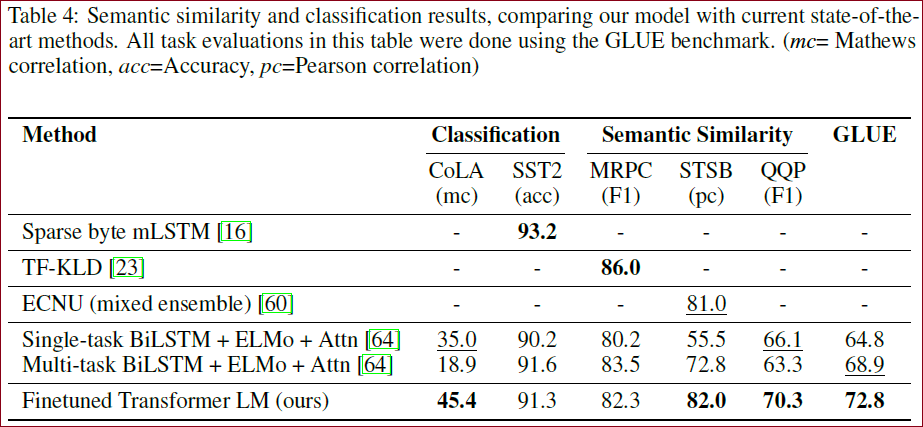
语义相似性涉及预测两个句子在语义上是否等效。作者使用3个数据集进行评估,在其中2个上达到了最先进的结果。
分类(Classification)
最后评估了分类任务,在SST-2和CoLA上都具有竞争力的结果。
分析
层的影响(Impact of number of layers transferred)
作者观察了模型层数对预训练知识迁移到下游任务的影响。
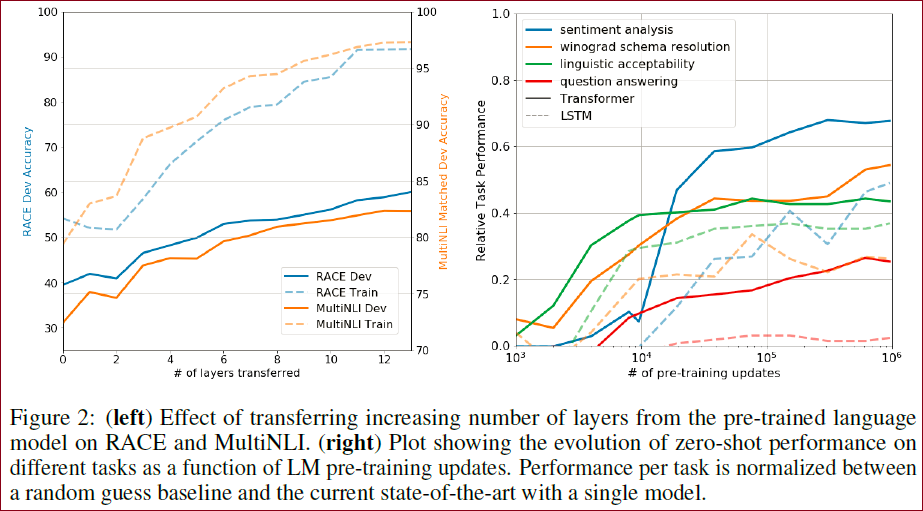
上图左边展示了模型层数对MultiNLI和RACE任务的性能变化。观察到每增加一层会提升9%的性能,说明预训练模型中每一层都包含用于解决目标任务的知识。
上图右边可视化了启发式解决方案在生成预训练模型过程中的有效性。作者希望更好理解为什么预训练是有效的。一个假设是,底层的生成模型通过执行多任务预训练提高了语言建模能力,并且注意力机制有利于迁移。观察到模型性能随着预训练的更新稳定增加,表明预训练支持学习各种任务相关功能。
消融实验
消融实验的作用:通过消融实验等手段验证GPT模型中各个组成部分的作用和有效性。
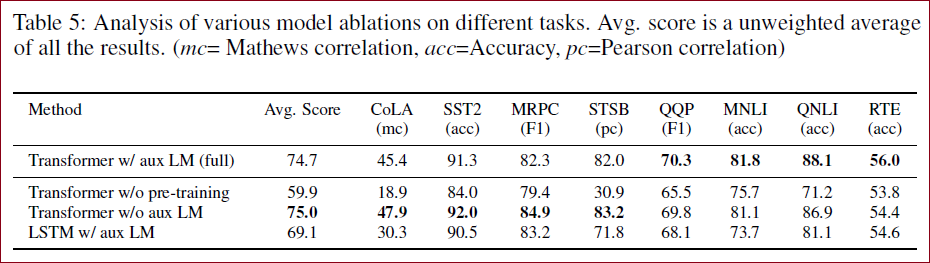
消融实验结果见上表,观察到:
越大的数据集受益于辅助目标,但较小的数据集相反;
Transformer架构优于LSTM架构;
缺乏预训练会损害所有任务的性能。
如何应用GPT模型
博文9指出:
实际上,利用GPT模型进行自然语言处理任务并不需要深厚的专业知识。通过调用GPT模型提供的API接口,我们可以轻松地实现文本生成、问答、文本分类等任务。此外,我们还可以根据自己的需求对GPT模型进行微调(fine-tuning),以适应特定领域和场景的需求。
总结
本文设计了GPT,通过预训练和微调,实现了强大的自然语言理解能力。本文的工作证明,实现显著的性能提升是可能的。
文章提出了一种生成式预训练+微调的语言训练方法,更有效地捕获到语言模型结构。
作者希望有助于对自然语言理解和其他领域的无监督学习进行新的研究,进一步提高我们对无监督学习如何以及何时发挥作用的理解。
本文的研究成果为自然语言处理领域的发展提供了一个新的思路和方法。
【博文2】的总结
本文(GPT)是NLP大模型时代的经典基石文章。
正是GPT的提出,才有了BERT,才有了chatGPT,才有了现在NLP大模型领域的百家争鸣。
虽然GPT本质上是Transformer的解码器的堆叠,但是它创新性提出了预训练和微调的学习范式,为之后的大模型发展奠定了基础。
说到GPT,就不得不提到BERT,从引用量来说,BERT远超过GPT,但是不代表BERT就优于GPT,虽然从实验结果上BERT优于GPT,但是细读BERT可以发现,BERT许多地方都借鉴了GPT,包括预训练和微调的范式,所以BERT虽然让预训练+微调的方式出圈了,但是真正的贡献还是来自于GPT。当然,正是因为BERT的出现,让GPT意识到自己的不足,即解码器和编码器架构本身的不同,正式架构的不同,才让二者的预训练任务不同,所需要的训练数据规模和模型规模也就不同,因此GPT的后续工作才会在更大规模的数据集上预训练,在模型层数上下功夫。
【博文3】提及的BERT & GPT
BERT和GPT是当下最受欢迎的两种预训练模型。
二者均采用Transformer架构。
| BERT | GPT | |
|---|---|---|
| Transformer架构 | 采用双向Transformer架构(解码部分) | 采用单向Transformer架构(编码部分) |
| 预训练方式 | 采用的是掩码预测方式 | 采用的是生成式预训练 即,通过前面的token预测当前token。 这也间接要求GPT采用单向Transformer架构。 |
【博文4】的思考
1 为什么GPT模型的网络结果必须采用解码器 —— 自回归性质
GPT预训练模型仅仅只采用transformer的解码器(decoder),是源于解码器中的第一层多头注意力(Multi-Head Attention)采用了掩码(Masked)的操作,具体操作类似于输入图像只裁剪中间信息,将部分像素通过与掩码矩阵相乘进行消除,使得输出时只能获取未被掩码掉的部分,而论文中采用该方法,将k作为上下文窗口,涂抹掉信息来预测下一个词。这种掩码操作被称为自回归性质,它可以确保模型在生成序列时遵循语言的线性顺序,而不会出现随意跳跃或重复生成的情况。这样,通过大量的文本数据来预训练该模型,可以使其学习到自然语言中的语法结构、词汇等知识。
2 为什么GPT的位置嵌入没有使用Transformer的位置编码
GPT的位置嵌入并没有使用原transformer的正弦函数(sinusoidal)的方式求得。其中transformer提出的方式见如下公式。经过查阅,发现Bert也不是采用transformer的正弦函数,可能自学习的位置嵌入更加贴合数据集,并且目前的单一输入文本长度也不会过长,但在将来越来越大的数据集下,这种可以扩展到无限长度的方式本身具有的泛化性可能会更加有优势。
结论
GPT这篇论文奠定了ChatGPT的基础,GPT2论文和GPT3论文主要是对预训练方式的改进和不断地增大模型的参数。
Instruct GPT提出的RLHF,就是基于人类反馈(Human Feedback)对语言模型进行强化学习(Reinforcement Learning),人工训练出一个符合人类行为或反馈的奖励模型,然后利用PPO算法进行语言模型的微调,即以强化学习方式依据人类反馈优化语言模型,自此ChatGPT才得以从量的累积到质的改变,并且这也是ChatGPT能很好避开违法犯罪、种族歧视等话题的一种最为有效的手段。
这篇论文为我们揭示了GPT模型如何通过生成式预训练提升语言理解能力的奥秘。
GPT1: Improving Language Understanding by Generative Pre-Training - 论文精读学习笔记介绍数据集相关工作框架3.1 无监督学习下的预训练(Unsupervised pre-training)3.2 监督学习下的微调 (Supervised fine-tuning)3.3 特定任务的输入转换(Task-specific input transformations)不同微调任务的输入Textual entailmentSimilarityQuestion Answering and Commonsense Reasoning实验4.1 实验设置无监督预训练模型规范微调细节4.2 监督微调自然语言推理(Natural Language Inference)问题回答和常识推理语义相似性(Semantic Similarity)分类(Classification)分析层的影响(Impact of number of layers transferred)消融实验如何应用GPT模型总结原文目录参考博文
原文目录
1 Introduction 1 2 Related Work 2 3 Framework 3 Unsupervised pre-training 3 Supervised fine-tuning 3 Task-specific input transformations 4 4 Experiments 4 Setup 4 Supervised fine-tuning 5 5 Analysis 7 6 Conclusion 8
参考博文
【论文阅读】Improving language understanding by generative pre-training
点评:应该是全文的翻译,没有重点或者思考可以汲取,所以没看完
【NLP经典论文精读】Improving Language Understanding by Generative Pre-Training
点评:有自己的思考,还有一些引申,很不错
论文笔记--Improving Language Understanding by Generative Pre-Training
点评:简短、但比较精准,比博文2更详细、准确些
GPT的前身:Improving Language Understanding by Generative Pre-Training 论文阅读
点评:简短且有自己的思考,不错的博文
GPT1(Improving Language Understanding by Generative Pre-Training)论文阅读 Google
点评:写的不错,需要外网才能看。引文值得再看看
GPT之《Improving Language Understanding by Generative Pre-Training》: 预训练的力量
点评:博文提供了一些预备知识,我觉得不错
GPT1论文笔记(Improving Language Understanding by Generative Pre-Training)
点评:一点点内容,但是能帮助我从更高的层次理解文章
GPT-1论文《Improving Language Understanding by Generative Pre-Training》解读
点评:博文提供的总结图很赞,我给摘录了过来,鼓励大家看原文👆
LLMs之GPT:《Improving Language Understanding by Generative Pre-Training》的精髓解读
点评:特别解释了“生成式预训练”的一些概念和内容,帮助我又加深了一些理解
博文免责声明
本条博文信息主要整合自网络,部分内容为自己的理解写出来的,如有断章截句导致不正确或因个人水平有限未能详尽正确描述的地方,敬请各位读者指正;
引用出处可能没有完全追溯到原始来源,如因此冒犯到原创作者,请联系本人更正/删除;
博文的发布主要用于自我学习,其次希望帮助到有共同疑惑的朋友。